
GitLab consommait 4.49 GiB de RAM en moyenne sur mon cluster perso. Forgejo en consomme 314 MiB. Même usage Git + CI, même cluster Kapsule, 14× moins de mémoire. Voilà ce que ça a donné, et les trois galères traversées au passage.
Pourquoi GitLab au départ, pourquoi plus
git.z3k.eu tournait sur GitLab Helm depuis un moment. La full-suite : Rails app, Sidekiq, Gitaly, Workhorse, registry, runners, le tout backé par CNPG PostgreSQL et Valkey, OIDC branché sur Authentik, SSH sur le 2222 via une IngressRouteTCP Traefik. C’était propre, ça marchait.
Le problème c’est que je suis tout seul derrière. Je pousse du code, je fais tourner de la CI, point. 90% des fonctionnalités GitLab dorment. Et même en désactivant proprement tout ce qui est désactivable côté chart (registry, KAS, mailroom, runner, prometheus…), le core reste lourd : Rails Webservice, Workhorse, Gitaly, Sidekiq, Postgres, Redis, gitlab-shell. Tous interdépendants, tu n’arrives pas à descendre en-dessous de plusieurs GiB.
Sur un cluster à quatre nodes Scaleway, ce poids commençait à se voir.
Les chiffres avant/après
J’ai laissé tourner les deux en parallèle quelques jours pour avoir une mesure honnête.
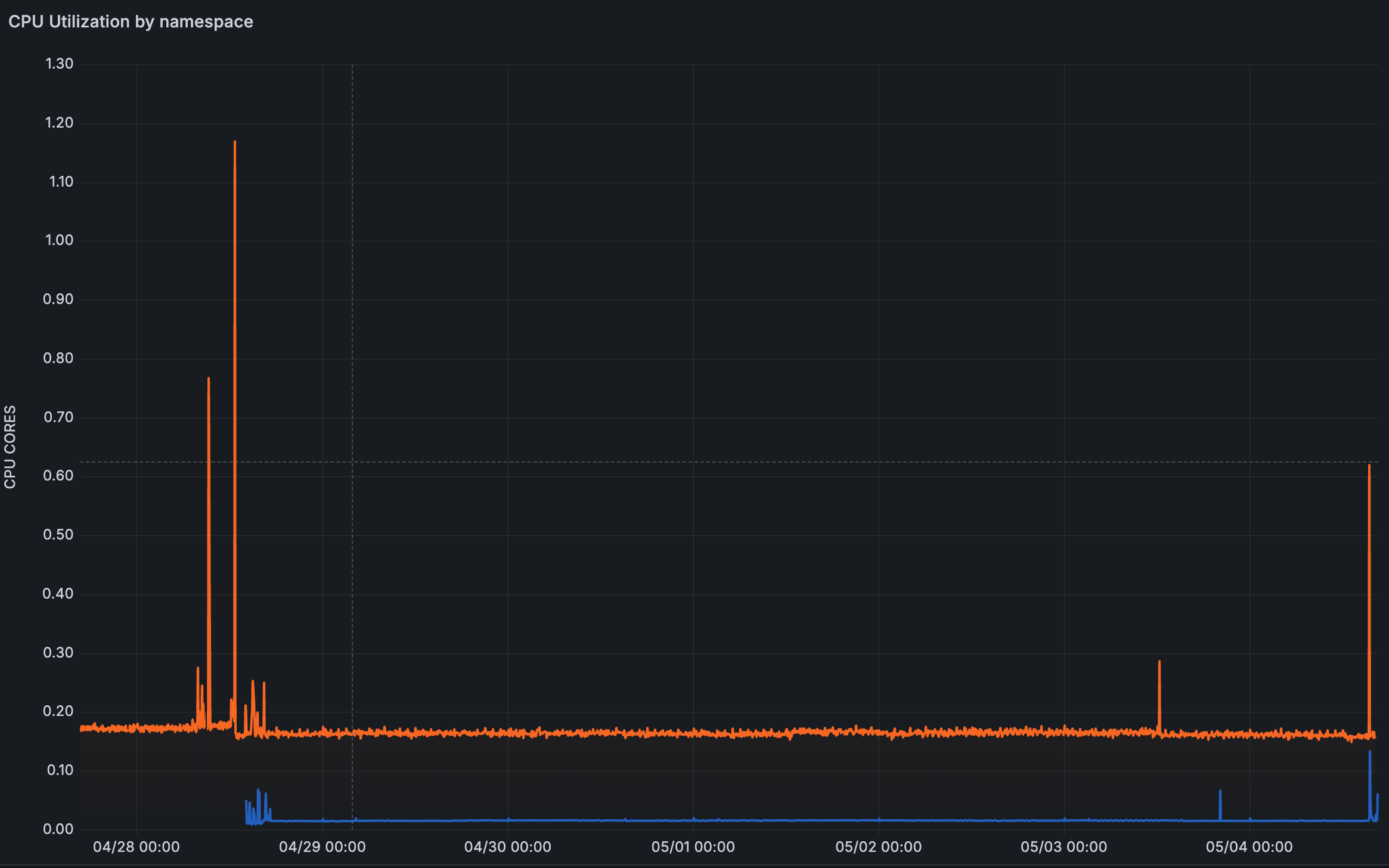
→ CPU moyen : GitLab 0.17 cores / Forgejo 0.02 cores (8× moins) → CPU max : GitLab 0.81 / Forgejo 0.12
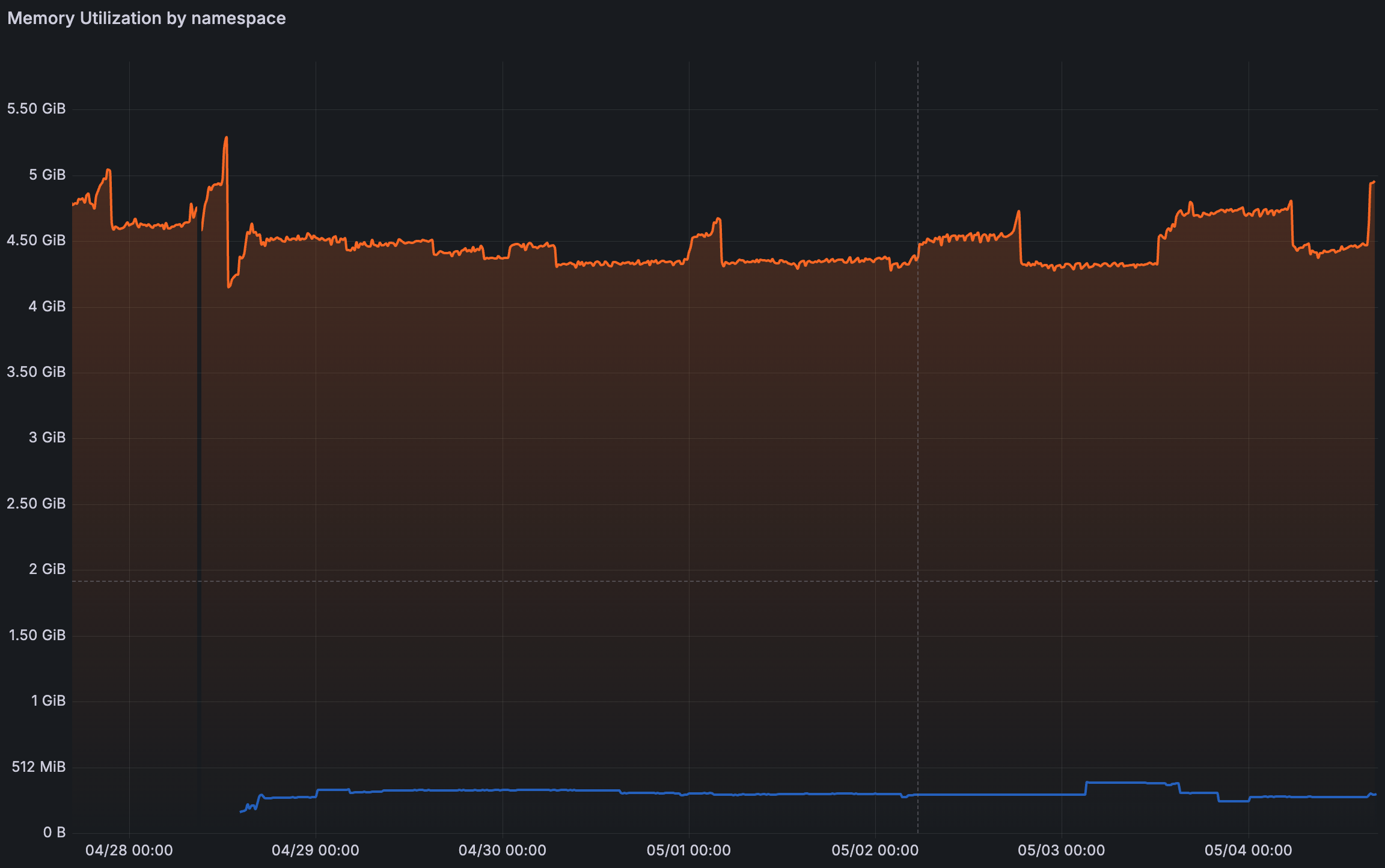
→ Mémoire moyenne : GitLab 4.49 GiB / Forgejo 314 MiB (14× moins) → Mémoire max : GitLab 5.29 GiB / Forgejo 396 MiB
Sur un cluster Kapsule, libérer 4 GiB de mémoire et 0.15 core, c’est concrètement un node de moins à terme. Ce qui s’est passé après le ménage, j’y reviens.
La nouvelle stack
Forgejo via Helm sur git.z3k.eu, SSH 2222 via IngressRouteTCP Traefik (j’ai gardé exactement le même pattern d’URL pour pas casser mes remotes locaux). Backend PostgreSQL CNPG, comme avant. OIDC vers Authentik, comme avant.
La grosse réjouissance c’est Forgejo Actions. Le marketplace pointe sur code.forgejo.org, mais surtout les workflows sont compatibles avec GitHub Actions. Concrètement, mes .gitea/workflows/*.yaml ressemblent à du .github/workflows/*.yaml, je peux réutiliser des actions tierces. Pas de réécriture de CI à faire en migrant, c’est l’argument central.
Côté runner : un deployment dédié avec code.forgejo.org/forgejo/runner:6 et un sidecar Docker-in-Docker en TCP plain sur localhost:2375. Pas de TLS, le sidecar tourne dans le même pod, l’isolation réseau est suffisante. J’expose deux labels : docker:docker://node:20-bookworm et buildah:docker://quay.io/buildah/stable. La registration est persistée sur PVC pour ne pas brûler de token à chaque restart.
Le hot swap : trois galères
LevelDB et le multi-replica impossible
Forgejo embarque LevelDB en interne pour ses queues, son cache et ses sessions. LevelDB pose un file-lock sur /data/queues/common. Conséquence directe : tu ne peux pas faire tourner deux replicas sur le même PVC, le second pod refuse de démarrer.
J’ai donc dû forcer le deployment en strategy: Recreate. Chaque upgrade = ~30s de downtime. Pour mon usage perso ça passe, mais c’est un caveat honnête à connaître si tu vises du HA. La roadmap Forgejo prévoit de migrer ces queues vers Redis/Valkey, ce qui débloquera le multi-replica. En attendant, c’est Recreate ou rien.
Le runner enregistré sur le mauvais domaine
Premier déploiement du runner. Il démarre, log spam :
dial tcp: lookup forgejo.z3k.eu: no such host
Toutes les deux secondes. Le runner cherchait forgejo.z3k.eu au lieu de git.z3k.eu. Ma faute : j’avais d’abord testé avec forgejo.z3k.eu comme variable d’environnement avant de standardiser sur git.z3k.eu. Le runner s’était enregistré avec cette URL et l’avait persistée dans /data/.runner sur son PVC.
Le piège c’est que le runner ne fait sa registration que si /data/.runner n’existe pas. Donc redémarrer le pod ne change rien : il relit le fichier obsolète et continue à interroger le mauvais domaine. Ré-enregistrer proprement aurait demandé de regénérer un token côté UI, recréer le PVC, et perdre l’identité du runner.
J’ai pris au plus court : kubectl exec dans le pod, sed in-place sur /data/.runner pour patcher le domaine, restart du deployment. Runner ID préservé, token préservé, ça repart. Petit gotcha à connaître si tu te trompes d’URL au premier coup.
L’autoscaler qui refuse de scale down
Une fois GitLab supprimé, je m’attendais à voir le cluster passer de 4 à 3 nodes en quelques minutes. Trente minutes plus tard : toujours 4 nodes. La charge tenait pourtant largement sur 3.
J’ouvre les events du cluster autoscaler. Le scale-down était bloqué pour deux raisons :
D’abord, 19 pods utilisaient un emptyDir sans annotation cluster-autoscaler.kubernetes.io/safe-to-evict: "true". Par défaut, l’autoscaler refuse d’évacuer un pod avec un emptyDir parce qu’il considère que les données dedans peuvent être importantes. Pour des composants stateless comme Traefik ou l’opérateur CNPG, ce ne l’est pas, mais l’autoscaler ne le sait pas.
Ensuite, les PDB des PostgreSQL primaires CNPG étaient à 0 allowed disruptions. Logique : tu ne veux pas évincer un primaire Postgres comme ça. Cette partie-là est correcte, je l’ai laissée telle quelle.
Le fix : j’ai annoté Traefik et l’opérateur CNPG en safe-to-evict: "true" (composants stateless, leur emptyDir est jetable), et laissé les PDB Postgres tranquilles. Quelques minutes après, l’autoscaler a fait son boulot. Passage à 3 nodes.
L’insight : virer un gros workload ne suffit pas à scaler down. Il y a toujours des pods qui traînent et qui bloquent l’éviction sans qu’on s’en rende compte. Dans 80% des cas c’est un emptyDir non annoté ou un PDB trop strict.
Edit (mai 2026) : la quatrième galère, révélée par un changement de cluster
Quelques semaines après, j’ai déplacé le cluster sur Hetzner avec Talos et Cilium. Migration de l’infra propre, Forgejo en place, tout vert. Premier push qui déclenche la CI :
Error: authenticating creds for "rg.fr-par.scw.cloud/z3k-tech":
pinging container registry rg.fr-par.scw.cloud:
Get "https://rg.fr-par.scw.cloud/v2/": net/http: TLS handshake timeout
Symptôme trompeur. Depuis le pod runner, curl https://rg.fr-par.scw.cloud/v2/ répond en 100 ms. Depuis le sidecar dind, idem. Même en spawn manuel d’un node:20-bookworm dans le dind, ça passait. Mais sous exécution réelle d’un job par act_runner : timeout systématique au TLS handshake.
Le piège tient à la manière dont act_runner isole les jobs. Pour chaque task il crée un docker network dédié (FORGEJO-ACTIONS-TASK-<id>) via docker network create. Sans flag explicite, ce network prend la valeur Docker par défaut : MTU 1500. Mes pods Cilium tournent en VXLAN avec MTU 1450. Les paquets de TLS Server Hello (Certificate, ~3-5 KiB) ont le bit DF positionné, dépassent 1450 quelque part dans la chaîne, et se font dropper silencieusement. Pas d’ICMP fragmentation-needed qui remonte au client, donc l’appli attend bêtement 10s puis timeout.
Et donc tout ce qui sortait du cluster vers une registry externe (Scaleway, Docker Hub) s’effondrait dès que la handshake TLS dépassait quelques centaines d’octets — c’est-à-dire toujours.
Le fix tient en une ligne dans /etc/runner/config.yaml du runner :
container:
privileged: true
docker_host: tcp://localhost:2375
network: bridge
Avec network: bridge, act_runner réutilise le bridge par défaut au lieu d’en créer un par job. Ce bridge-là hérite du --mtu=1450 qu’on a passé au dockerd dans le dind. Les containers de job y sont attachés, MTU correct, TLS s’ouvre normalement.
Le leçon : un symptôme TLS handshake timeout n’est presque jamais un problème TLS. Sur un cluster CNI overlay, c’est neuf fois sur dix un MTU mismatch. Et le piège supplémentaire avec act_runner, c’est qu’il ignore proprement les défauts du daemon Docker pour le network qu’il crée lui-même.
Le bilan FinOps
Quatre nodes à trois nodes sur Kapsule, à environ 25-30 €/mois le node, ça paye les cafés du mois. Mais le gain n’est pas que sur la facture.
Moins de pods, c’est aussi moins de PDB à suivre, moins de surfaces de panne, moins de bruit dans les alertes, des upgrades plus rapides. Quand tu hostes seul ton infra perso, ce bruit opérationnel compte autant que les euros.
GitLab full-suite n’a rien d’un mauvais produit. Pour une équipe qui utilise vraiment les boards, les MRs avec approbations multiples, le registry, le SAST intégré, les environnements de review, ça se justifie. Mais pour 90% des cas où tu fais hosting Git + CI, Forgejo (ou Gitea) couvre le besoin avec un dixième de la facture mémoire.
Ce que j’en retiens
Migrer un GitLab vers Forgejo, ça prend une demi-journée si tu connais les deux outils. Les gains de ressources sont réels et mesurables. Les caveats existent : le LevelDB lock empêche le HA propre, et il faut être attentif à l’URL au moment d’enregistrer les runners.
Et surtout : penser à débloquer l’autoscaler après avoir viré le gros workload. Sinon le cluster reste à sa taille d’avant et le gain FinOps ne se matérialise jamais sur la facture.
Points clés à retenir
- ✓ Forgejo consomme 314 MiB de RAM en moyenne contre 4.49 GiB pour GitLab full-suite, sur le même cluster, pour le même usage Git + CI
- ✓ Forgejo Actions est compatible avec les workflows GitHub Actions : pas de réécriture de pipelines en migrant
- ✓ Caveat HA : Forgejo embarque LevelDB qui pose un file-lock sur le PVC, donc deployment forcé en Recreate, ~30s de downtime par upgrade
- ✓ Virer GitLab ne suffit pas à scaler down le cluster : il faut aussi annoter les pods avec emptyDir en safe-to-evict pour débloquer l'autoscaler
- ✓ Sur un cluster CNI overlay (Cilium VXLAN, MTU 1450), act_runner crée un docker network par job avec MTU 1500 par défaut. Symptôme : TLS handshake timeout en CI. Fix : container.network: bridge dans le config.yaml du runner